好的东西,推荐给大家!希望大家每一天都有新的发现!
Software:GooReader
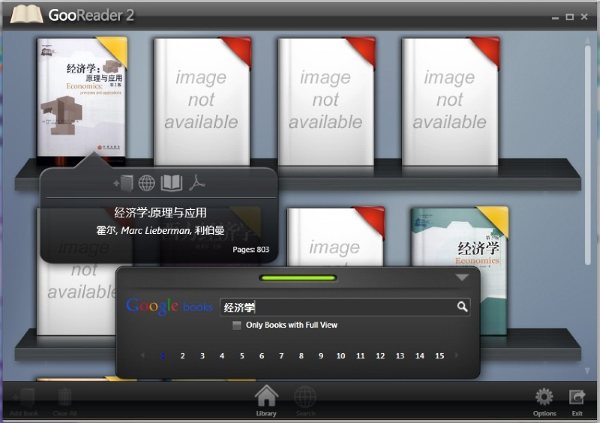
Google Books里有很多值得一读的好书,不过网页版用户体验做的确实是差了点,不仅有点卡还让你感觉不出是在读一本书。
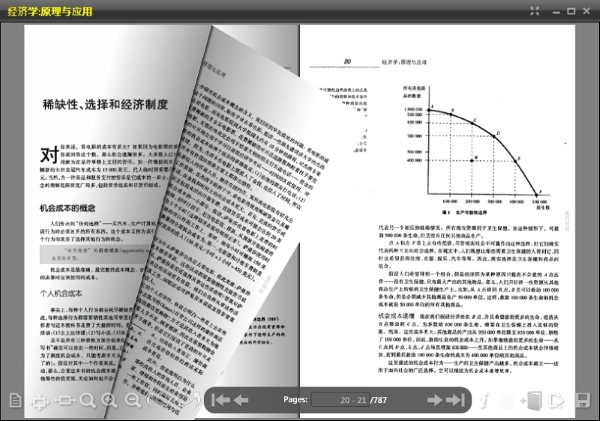
好在有GooReader,这个Windows下的应用程序可以让你直接搜索Google Books里的图书,并在书架上直接阅读,带有绿色书签的书可以直接阅读,而红色标签的书则表示无法阅读全文(Google Books的限制)。打开一本书之后你可以缩放(不过不一定保证清晰,取决于Google的扫描质量),不过目前无法加书签也无法将一本书加入收藏。
GooReader有免费版和付费版,区别在于是否可以将图书存为PDF格式保存,目前仅有Windows版本,且需要装有.NET 3.51 SP1。
还可以将自己电脑里面的PDF格式的书籍,用GooReader来管理,非常方便!
Game:Machinarium:机械迷城
《Machinarium:机械迷城》由捷克独立开发小组Amanita Design设计制作的作品,此作堪称以独特的水墨风格展现给玩家的是一款冒险解谜游戏,对于我这个不怎么喜欢玩游戏的人来说,它的确挺好玩的,不过因为休息时间比较少,每天也就玩一小会儿,不过真的很不错,推荐给大家。
游戏将采用传统点击式界面,和Samorost游戏相似,2D背景和人物,没有对白.不过,Machinarium游戏时间将更长更复杂,画面将由手画,而玩家有个小物品栏。 Machinarium中每个人都是机器人,包括我们的小英雄,他将对从 “Black Cap Brotherhood”来的坏人。本游戏在2009年独立游戏节上斩获了视觉艺术奖。

Music:第六交响曲(悲怆)
柴可夫斯基的第六交响曲(悲怆)大约在1893年八月末至九月间完成,为作者的代表作。柴科夫斯基自认为这部交响曲是他一生中最成功的作品,也是他最得意的杰作。本曲首演于同年的十月二十八日,六天之后,作者不幸染上霍乱,与世长辞。本曲终成为柴科夫斯基的“天鹅之歌”。
这首交响曲正如标题所示,强烈地表现出“悲怆”的情绪,这一点也就构成本曲的特色。柴科夫斯基音乐的特征,如旋律的优美,形式的均衡,管弦乐法的精巧等优点,都在本曲中得到深刻的印证,因此本曲不仅是柴科夫斯基作品中最著名、最杰出的乐曲之一,也是古今交响曲中第一流的精品。
本交响曲旨在描写人生的恐怖、绝望、失败、灭亡等,充满了悲观的情绪,而否定了一切肯定、享受人生的乐观情绪。作者在本曲中也刻意描写了人们为生活而奔忙的情景,但他揭示了一个永恒的真理——死亡是绝对的、无可避免的,而生活中的所有欢乐都是转瞬即逝的。作者所体现出的这类情绪,实际上反映的是在沙皇俄国末期,俄罗斯人民处于一种被压抑状况下的真实心态。
本曲虽属于标题音乐,但决不是针对某一特定事件或某一特殊个人的感情描写,只是以抽象手法表现人类共同具有的悲怆情绪而已。因此有的乐评家认为,本曲不应视为纯粹的标题音乐。
全曲共分为四个乐章:
第一乐章 慢板,转不很快的快板,b小调,4/4拍子,奏鸣曲形式。序奏为慢板,低音提琴以空虚的重音作为引子,由低音管在低音区演奏出呻吟般的旋律,其他乐器则如叹息般地继续。乐曲自开始就笼罩在一种烦躁不安的阴沉气氛中。主部的第一主题快速而富节奏感地奏出,给人以苦恼、不安和焦燥的印象。之后乐曲的速度旋即转成行板,第二主题哀愁而美丽,有如暂时抛却苦恼而沉入幻想中一般(片段1)。本乐章的终结部十分柔美、温和,旋律在平静的伴奏下伸展,形成谜一样的结尾。
第二乐章 温柔的快板,D大调,5/4拍子。自始自终 一贯单纯的色彩,其构想似乎来自俄罗斯民谣。5/4拍子的分配方式为, 各小节的前半部分为二拍,后半部分为三拍,形成了不安定而又稍快的音乐,全乐章呈现出昏暗、低迷的状态。主部的主要旋律具有舞蹈般的节奏,却又荡漾着一丝不安的空虚感(片段2)。
第三乐章 甚活泼的快板,G大调,4/4拍子,谐谑曲与进行曲混合而无发展部的奏鸣曲式。这一乐章的主要内容反映了人们四处奔忙、积极生活的景象,有人认为这一乐章体现出作者对过去的回忆。本乐章第一主题为谐谑曲式,轻快、活泼,与前两个乐章的主题形成对比(片段3)。 乐章的第二主题很像意大利南部的一种民族舞蹈音乐——塔兰泰拉舞曲,其主要旋律具有战斗般的感觉,但这一主题在进行曲般的旋律中,并没有明朗、快活的气息,反而呈现出一种悲壮感。 这一主题旨在表现人类的苦恼爆发时,所发泄出的反抗力量(片段4)。 此部分略经扩展后,再次出现诙谐曲主题而达到高潮。紧接着进行曲主题再现,乐章的终结部便在进行曲主题片断堆积的形态下强烈地结束。
第四乐章 终曲,哀伤的慢板,b小调,3/4拍,自由的三段体。 本乐章的主题极为沉郁、晦暗(一般交响曲的终曲都是最为快速、壮丽的乐章,而本交响曲正相反,充分强调了“悲怆”的主题),悲伤的旋律在两声圆号的衬托下显得更加凄凉(片段5)。 本乐章在无限凄寂当中结束。这一乐章正如本交响曲的标题,描写人生的哀伤、悲叹和苦恼,凄怨感人,有深沉的悲怆之美。